




Graphe hybride + vecteur
Similarité sémantique et contexte relationnel interrogés ensemble pour une précision qu’aucun des deux n’atteint seul.
/ Enterprise Knowledge AI /
Enterprise Knowledge AI relie chaque document, système et source de données en une seule couche d’intelligence gouvernée — et offre à vos équipes des réponses instantanées, précises et ancrées dans les sources.
Pourquoi la connaissance d’entreprise se dégrade
La plupart des organisations disposent de plus de savoir institutionnel qu’elles ne peuvent consulter. Il repose dans des dossiers que personne ne parcourt, des wikis que personne ne lit, et dans la tête de quelques experts. Résultat : travail dupliqué, décisions lentes et départ du savoir.
SharePoint, Drive, Confluence, Notion, e-mail, fichiers locaux — chaque équipe a son système et ils se connectent rarement.
La recherche par mots-clés trouve des fichiers. Elle ne répond pas aux questions. Les utilisateurs lisent encore cinq documents — si le bon apparaît.
Des politiques obsolètes côtoient les actuelles. L’IA non gouvernée au-dessus renvoie des erreurs avec une fausse certitude.
Sans attribution, confiance et piste d’audit, les réponses de l’IA ne sont pas acceptables dans les environnements réglementés ou à enjeux élevés.
Définition du produit
Similarité sémantique et contexte relationnel interrogés ensemble pour une précision qu’aucun des deux n’atteint seul.
Récupération et synthèse multi-étapes — pas une seule recherche vectorielle — avec détection des lacunes et nouvelle récupération si besoin.
Permissions héritées des systèmes sources, application au moment de la récupération, scores de confiance et journaux d’audit immuables.
Orchestration entreprise, routage des modèles et patterns opérationnels de la plateforme Thinkia Synapse.
Architecture
Connecteurs (OAuth/API), découpage sémantique, OCR pour scans, métadonnées préservées, synchronisation incrémentielle pour maîtriser les coûts.
Recherche vectorielle pour la similarité ; graphe de connaissance pour entités et relations (ex. remplace, s’applique_à, propriété_de).
Décomposition des requêtes, récupération parallèle, classement, synthèse fondée, citations et confiance — avec boucle d’agent pour requêtes complexes.
RBAC/ABAC, scores de confiance par source, piste d’audit immuable, contrôles d’hallucination. Supervision humaine et explicabilité orientées EU AI Act ; alignement avec ISO/IEC 42001 et documentation NIST AI RMF.
Application web, Teams, Slack, extension navigateur, widget intégrable, API REST/streaming, OpenAPI et SDKs.
Les références à l’EU AI Act, ISO/IEC 42001 et NIST AI RMF décrivent l’orientation produit et des schémas de documentation — pas un conseil juridique pour votre cas précis.
Boucle de récupération en un coup d’œil
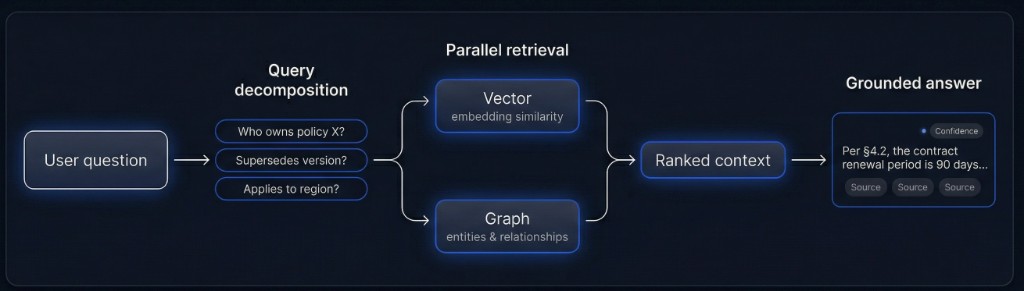
Les questions complexes sont divisées en sous-requêtes avant récupération pour réduire le bruit et le coût en tokens.
Requêtes vecteur et graphe en parallèle ; résultats classés, dédupliqués et pondérés par la confiance.
Le modèle répond uniquement à partir du contexte classé ; les affirmations renvoient aux extraits sources avec confiance.
Parcours de mise en œuvre
Cartographier sources, volumes, modèles d’accès et cas d’usage prioritaires. Livrable : note d’architecture et plan d’ingestion.
Déployer connecteurs, découpage/embeddings/extraction graphe, configurer l’accès. Livrable : base consultable et consciente des permissions.
Évaluer la qualité de récupération, affinage optionnel des embeddings métier, seuils de confiance. Livrable : rapport de qualité validé.
Cohorte pilote, analytics résolution/escalade, baselines temps de réponse. Livrable : système en production avec mesure.
Étendre sources et utilisateurs, boucles de retour, rapports de lacunes pour améliorer la documentation.
Connecteurs
Connecteurs OAuth et API — le contenu reste à la source ; les réponses n'utilisent que ce que chaque utilisateur peut voir.
Le catalogue exact des connecteurs et les options de déploiement sont convenus par engagement.
Collaboration
Fichiers et contenu
Systèmes et données
Métriques qui comptent
Objectifs et KPI convenus par déploiement — pas de chiffres universels
<3s
Vitesse — temps jusqu’à la réponse (p95)
Bout en bout pour requêtes typiques ; chemins agentiques complexes plus longs — voir la note technique.
<20m
Vitesse — propagation des mises à jour (p95)
Délai illustratif entre changement source et extraits rafraîchis avec webhooks ; environnements très batch suivent des plannings convenus — ajusté par engagement.
>90%
Précision — qualité fondée
Cibles typiques après réglage : precision@k et/ou précision des réponses fondées >90%, taux d’affirmations non supportées <1% — validé sur jeux hold-out par corpus.
>85%
Précision — rappel et couverture
Objectifs recall@k et couverture du corpus souvent >85% lorsque la réponse existe dans les sources — mesuré avec bancs d’évaluation.
50–70%
Coût — vs RAG naïf
Fourchette typique avec routage, cache, découpage et compression — illustratif, pas une garantie.
Prêt pour audit
Traçabilité — piste conformité
Requête, sources, modèle et confiance journalisés pour les workflows de conformité.
Analyse comparative
Microsoft 365 est une référence ; beaucoup d’environnements restent un patchwork recherche, wikis et RAG maison — patterns illustratifs, pas d’affirmations fournisseur.
| Facteur | Copilot pour M365 | Pattern entreprise typique | Enterprise Knowledge AI |
|---|---|---|---|
| Couverture des sources | Focus écosystème Microsoft | Recherche et portails fragmentés par système. | Connecteurs étendus sur sources entreprise |
| Graphe de connaissance | Pas de couche relationnelle équivalente | Recherche par mots-clés sans parcours graphe+vecteur multi-sauts. | Hybride graphe + vecteur pour multi-sauts |
| Choix du modèle / BYOK | Parcours Azure OpenAI | Clés et outils dispersés ; politique inégale. | Routage multi-modèles et options BYOK |
| Déploiement | Modèle service cloud | SaaS éparpillé ; pas de périmètre unique gouverné. | Privé, hybride ou cloud — une couche gouvernée |
| Angle commercial | Souvent au poste (narration M365) | Licences en silos ; TCO et gouvernance fragmentés. | Packaging convenu par engagement |
Options de déploiement
La même couche de connaissance gouvernée — vous choisissez où tournent données, index et inférence, de l’air-gapped au cloud entièrement géré.
Déploiement complet dans votre périmètre — index et LLM auto-hébergés optionnels sur votre réseau. Contrôle maximal pour secteur réglementé et public.
Dans votre tenant AWS, Azure ou GCP : données et résidence dans votre périmètre, déploiement, mises à jour et monitoring gérés par Thinkia.
Environnement opéré par Thinkia, UE par défaut. Chemin le plus rapide vers pilote avec connecteurs OAuth — sans infra client à exploiter.
FAQ
Les connecteurs détectent les changements à la prochaine synchro (webhook ou planification). Contenu mis à jour re-découpé et ré-embarqué ; suppressions retirent les entrées d’index et révoquent l’accès immédiatement. Les réponses historiques peuvent être signalées dans les journaux.
Oui, lorsque les deux sont connectées et que l’utilisateur y a droit. Le graphe relie entités des systèmes de référence aux documents et messages pour des réponses couvrant contrats et données opérationnelles.
Dépend de la taille du corpus et des limites API source. Indicatif : petits corpus en heures ; très grands en semaines avec pipelines parallèles. Sync incrémentielle réduit le coût en régime — détails dans la note technique.
Le système répond à partir du contexte récupéré et autorisé. Si la preuve est faible ou absente : confiance plus basse, lacunes explicites ou résultat clair du type « pas assez dans les sources », pas une supposition assurée. Seuils et escalade ajustables selon votre posture de risque.
Les déploiements enterprise sont cadrés pour que votre corpus ne soit pas mélangé à un pool d’entraînement public. Avec BYOK ou inférence on-prem, les fournisseurs sont choisis selon vos accords. Les termes exacts vont au contrat et DPA — détaillés en avant-vente et revue sécurité.
Non. EU AI Act, NIST AI RMF et ISO/IEC 42001 décrivent l’orientation produit et des patterns documentaires — pas une classification juridique de votre cas. Pour le positionnement réglementaire, consultez vos conseils et les pages gouvernance Thinkia.
Les affirmations en conflit sont présentées avec les deux sources citées et le conflit signalé. Le système ne choisit pas silencieusement — la résolution reste au propriétaire du savoir. Le taux de conflit peut être suivi comme signal qualité.
Par défaut, le routage utilise des modèles plus petits pour requêtes simples et plus grands pour raisonnement complexe. BYOK permet vos fournisseurs préférés. On-prem : modèles open weights approuvés.
L’index est construit avec identité source et droits. À la requête, récupération et synthèse n’utilisent que les extraits autorisés — mêmes règles que SharePoint, Confluence, Drive ou votre source de vérité. Si l’utilisateur ne peut pas ouvrir un document à la source, il ne doit pas apparaître dans son contexte de réponse.
Patterns typiques : tenant privé, hybride (données et index chez vous, orchestration cloud optionnelle) ou cloud géré — selon résidence, réseau et achats. La note technique décrit les hypothèses ; nous alignons l’architecture cible en découverte.
Connecteurs courants : Microsoft 365 / SharePoint, Confluence, Google Drive, magasins de documents similaires, APIs et dépôts internes. Systèmes custom ou legacy : API, export ou plan connecteur dédié. Sources prioritaires convenues dans la feuille de route d’ingestion.
Get started
Parlez-nous de vos sources, modèle d’accès et équipes. Nous revenons vers vous avec une prochaine étape claire — orientation, périmètre pilote ou pistes gouvernance — sans pression commerciale.