




Grafo híbrido + vector
Similaridade semântica e contexto relacional consultados em conjunto para precisão que nenhum isolado alcança.
/ Enterprise Knowledge AI /
Enterprise Knowledge AI liga cada documento, sistema e fonte de dados numa única camada de inteligência governada — e dá às suas equipas respostas instantâneas, precisas e ancoradas nas fontes.
Porque o conhecimento empresarial falha
A maioria das organizações tem mais conhecimento institucional do que consegue aceder. Está em pastas que ninguém navega, wikis que ninguém lê e na cabeça de poucos especialistas. Resultado: trabalho duplicado, decisões lentas e conhecimento a sair pela porta.
SharePoint, Drive, Confluence, Notion, email, ficheiros locais — cada equipa tem o seu sistema e raramente se ligam.
A pesquisa por palavras-chave encontra ficheiros. Não responde a perguntas. Os utilizadores ainda leem cinco documentos — se o certo aparecer.
Políticas desatualizadas ao lado das atuais. IA sem governo por cima dessa pilha devolve erros com ar de certeza.
Sem atribuição, confiança e trilho de auditoria, as respostas de IA não são aceitáveis em ambientes regulados ou de alto risco.
Definição do produto
Similaridade semântica e contexto relacional consultados em conjunto para precisão que nenhum isolado alcança.
Recuperação e síntese em vários passos — não uma única consulta vectorial — com deteção de lacunas e nova recuperação quando necessário.
Permissões herdadas dos sistemas de origem, aplicação no momento da recuperação, pontuação de confiança e registos de auditoria imutáveis.
Orquestração enterprise, encaminhamento de modelos e padrões operacionais da plataforma Thinkia Synapse.
Arquitetura
Conectores (OAuth/API), segmentação semântica, OCR para digitalizações, metadados preservados, sincronização incremental para controlar custo.
Pesquisa vectorial por similaridade; grafo de conhecimento para entidades e relações (ex. substitui, aplica_a, propriedade_de).
Decomposição de consultas, recuperação paralela, ranking, síntese fundamentada, citações e confiança — com ciclo de agente para consultas complexas.
RBAC/ABAC, pontuações de confiança por fonte, trilho de auditoria imutável, controlos de alucinação. Supervisão humana e explicabilidade orientadas ao EU AI Act; alinhamento com ISO/IEC 42001 e documentação NIST AI RMF.
Web app, Teams, Slack, extensão de browser, widget incorporável, API REST/streaming, OpenAPI e SDKs.
As referências ao EU AI Act, ISO/IEC 42001 e NIST AI RMF descrevem a orientação do produto e padrões de documentação — não constituem aconselhamento jurídico para o seu caso específico.
Ciclo de recuperação num relance
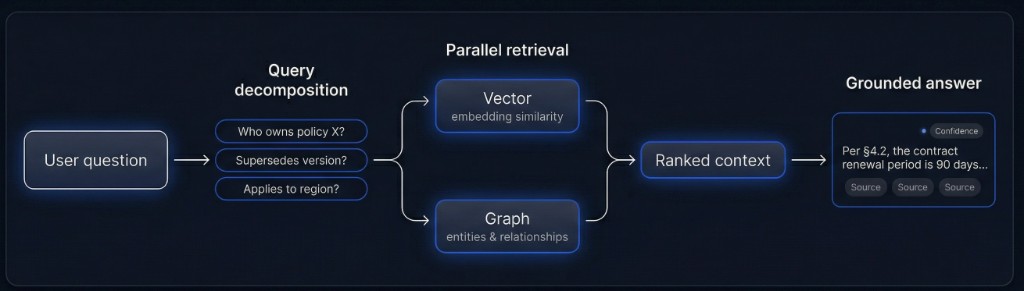
Perguntas complexas divididas em subconsultas antes da recuperação para reduzir ruído e custo de tokens.
Consultas vectoriais e de grafo em paralelo; resultados ordenados, deduplicados e ponderados por confiança.
O modelo responde apenas a partir do contexto ordenado; afirmações ligam a excertos de fonte com confiança.
Caminho de implementação
Mapear fontes, volumes, modelos de acesso e casos de uso prioritários. Entregável: brief de arquitetura e plano de ingestão.
Implementar conectores, segmentação/embeddings/extração de grafo, configurar acesso. Entregável: base pesquisável e consciente de permissões.
Avaliar qualidade de recuperação, fine-tuning opcional de embeddings de domínio, limiares de confiança. Entregável: relatório de qualidade validado.
Coorte piloto, analytics de resolução e escalação, linhas de base de tempo até resposta. Entregável: sistema em produção com medição.
Expandir fontes e utilizadores, ciclos de feedback, relatórios de lacunas de conhecimento para melhorar documentação.
Conectores
Conectores OAuth e API — o conteúdo fica na origem; as respostas usam apenas o que cada utilizador pode ver.
Catálogo exato de conectores e opções de implementação acordados por projeto.
Colaboração
Ficheiros e conteúdo
Sistemas e dados
Métricas que importam
Metas e KPI que acordamos por implementação — não números únicos para todos
<3s
Velocidade — tempo até resposta (p95)
Ponta a ponta para consultas típicas; caminhos agênticos complexos mais longos — ver brief técnico.
<20m
Velocidade — propagação de atualizações (p95)
Atraso ilustrativo desde alteração na fonte até excertos atualizados com webhooks; ambientes muito em lote seguem calendários acordados — afinado por projeto.
>90%
Precisão — qualidade fundamentada
Metas típicas pós-afinação: precision@k e/ou precisão de resposta fundamentada >90%, taxa de afirmações não suportadas <1% — validado em conjuntos hold-out por corpus.
>85%
Precisão — recall e cobertura
Objetivos recall@k e cobertura do corpus normalmente >85% quando a resposta existe nas fontes — medido com harness de avaliação.
50–70%
Custo — vs RAG ingénuo
Intervalo típico com encaminhamento, cache, segmentação e compressão — ilustrativo, não garantia.
Pronto para auditoria
Rastreabilidade — trilho de compliance
Consulta, fontes, modelo e confiança registados para fluxos de compliance.
Análise comparativa
Microsoft 365 é uma linha de base; muitos ambientes ainda têm pesquisa, wikis e RAG caseiro — padrões ilustrativos, sem afirmações específicas de fornecedor.
| Fator | Copilot para M365 | Padrão empresarial típico | Enterprise Knowledge AI |
|---|---|---|---|
| Cobertura de fontes | Foco no ecossistema Microsoft | Pesquisa e portais fragmentados por sistema. | Conectores alargados em fontes empresariais |
| Grafo de conhecimento | Sem camada relacional equivalente | Pesquisa por palavras sem percurso grafo+vector multi-salto. | Híbrido grafo + vector para multi-salto |
| Escolha de modelo / BYOK | Caminho Azure OpenAI | Chaves e ferramentas dispersas; política desigual. | Encaminhamento multi-modelo e opções BYOK |
| Implementação | Modelo de serviço cloud | SaaS disperso; sem perímetro único governado. | Privado, híbrido ou cloud — uma camada governada |
| Ótica comercial | Muitas vezes por posto (narrativa M365) | Licenças em silos; TCO e governação fragmentados. | Empacotamento acordado por projeto |
Opções de implantação
A mesma camada de conhecimento governada — escolhe onde correm dados, índices e inferência, de air-gapped a cloud totalmente gerida.
Implementação completa no seu perímetro — índices e LLM self-hosted opcionais ficam na sua rede. Máximo controlo para setor regulado e público.
No seu tenant AWS, Azure ou GCP: dados e residência no seu perímetro, com implementação, atualizações e monitorização geridas pela Thinkia.
Ambiente operado pela Thinkia, UE em primeiro lugar por defeito. Caminho mais rápido para piloto com conectores OAuth aos seus sistemas — sem infra do cliente a operar.
FAQ
Os conectores detetam alterações na próxima sincronização (webhook ou agendamento). Conteúdo atualizado é re-segmentado e re-incorporado; eliminações removem entradas do índice e revogam acesso de imediato. Respostas históricas podem ser assinalhadas nos registos.
Sim, quando ambos estão ligados e o utilizador tem direito a ambos. O grafo liga entidades dos sistemas de registo a documentos e mensagens para respostas que abrangem linguagem contratual e dados operacionais.
Depende do tamanho do corpus e dos limites da API de origem. Indicativo: corpora pequenos em horas; muito grandes em semanas com pipelines paralelos. Sincronização incremental mantém custos baixos em regime — detalhes no brief técnico.
O sistema responde a partir de contexto recuperado e autorizado. Com evidência fraca ou em falta: confiança mais baixa, lacunas explícitas ou resultado claro tipo «não há suficiente nas fontes» — não um palpite seguro. Limiares e escalação ajustáveis ao seu perfil de risco.
Implementações enterprise estão delimitadas para que o seu corpus não se misture num pool de treino partilhado de modelos públicos. Com BYOK ou inferência on-prem, os fornecedores são escolhidos nos seus acordos. Termos exatos em contrato e DPA — mapeamos em pré-venda e revisão de segurança.
Não. EU AI Act, NIST AI RMF e ISO/IEC 42001 descrevem orientação de produto e padrões documentais — não classificação legal do seu caso. Para posicionamento regulatório: o seu conselho jurídico e as páginas de governação Thinkia para orientação geral.
Afirmações em conflito são apresentadas com ambas as fontes citadas e o conflito assinalado. O sistema não escolhe silenciosamente um vencedor — a resolução fica com o dono do conhecimento. A taxa de conflito pode ser seguida como sinal de qualidade.
Por defeito, o encaminhamento usa modelos menores para consultas simples e maiores para raciocínio complexo. BYOK permite trazer os seus fornecedores preferidos. On-prem: modelos open-weights aprovados.
O índice é construído com identidade de origem e direitos. No momento da consulta, recuperação e síntese só usam excertos que o solicitante pode ver — as mesmas regras que no SharePoint, Confluence, Drive ou fonte de verdade. Se o utilizador não pode abrir um documento na origem, não deve aparecer no contexto da resposta.
Padrões típicos: tenant privado, híbrido (dados e índice do seu lado, orquestração cloud opcional) ou cloud gerida — conforme residência, rede e procurement. O brief técnico descreve pressupostos; alinhamos a arquitetura alvo na descoberta.
Conectores comuns incluem Microsoft 365 / SharePoint, Confluence, Google Drive e arquivo de documentos semelhante, mais APIs e repositórios internos. Sistemas personalizados ou legado normalmente via API, exportação ou plano de conector dedicado. Fontes prioritárias acordadas no roadmap de ingestão.
Get started
Conte-nos as suas fontes, modelo de acesso e equipas. Responderemos com um próximo passo claro — orientação, âmbito de piloto ou referências de governação — sem pressão comercial.