




混合图 + 向量
语义相似度与关系上下文联合查询,精度高于单独使用任一方式。
/ Enterprise Knowledge AI /
Enterprise Knowledge AI 将每份文档、每个系统与数据源接入单一受治理的智能层——为您的团队提供即时、准确、有据可查的答案。
企业知识为何失灵
大多数组织拥有的机构知识远超其可检索范围。它躺在无人翻的文件夹、无人读的维基和少数专家的脑子里。结果是:重复劳动、决策迟缓、知识随人流失。
SharePoint、Drive、Confluence、Notion、邮件、本地文件——各团队各用一套,彼此很少连通。
关键词搜索找到文件,不回答问题。用户仍要读五份文档——若正确的那份能出现的话。
过时政策与现行政策并存。缺乏治理的 AI 叠在上面会给出看似笃定实则错误的答案。
没有归属、置信度与审计轨迹,在受监管或高风险场景中,AI 答案不可接受。
产品定义
语义相似度与关系上下文联合查询,精度高于单独使用任一方式。
多步检索与综合——非单次向量查询——具备缺口检测与必要时重新检索。
权限继承自源系统,在检索时执行,含信任评分与不可变审计日志。
来自 Thinkia Synapse 平台的企业编排、模型路由与运营模式。
架构
连接器(OAuth/API)、语义分块、扫描件 OCR、保留元数据、增量同步以控制成本。
向量搜索相似度;知识图谱表示实体与关系(如取代、适用于、归属)。
查询分解、并行检索、排序、有据综合、引用与置信度——复杂查询带智能体循环。
RBAC/ABAC、来源信任分、不可变审计轨迹、幻觉控制。面向欧盟《人工智能法》的人监督与可解释性;与 ISO/IEC 42001 及 NIST AI RMF 文档对齐。
Web 应用、Teams、Slack、浏览器扩展、可嵌入组件、REST/流式 API、OpenAPI 与 SDK。
文中对欧盟《人工智能法》、ISO/IEC 42001 与 NIST AI RMF 的引用描述产品取向与文档化模式——不构成针对您具体用例的法律意见。
检索循环一览
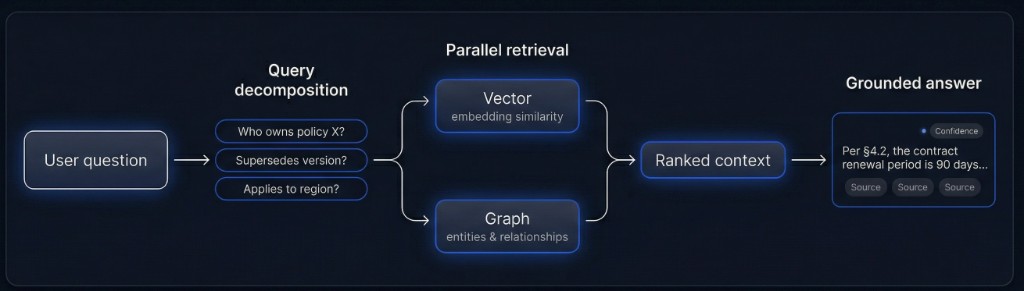
复杂问题在检索前拆成子查询,降低噪声与 token 成本。
向量与图查询并行执行;结果排序、去重并按信任加权。
模型仅基于排序后的上下文作答;论断链接到源片段与置信度。
实施路径
梳理来源、体量、访问模型与优先用例。产出:架构简报与摄取计划。
部署连接器,运行分块/嵌入/图抽取,配置访问。产出:可搜索、懂权限的基础。
评估检索质量,可选领域嵌入微调,设定置信阈值。产出:经验证的质量报告。
试点人群、解决与升级分析、首答时间基线。产出:可度量的在线系统。
扩展来源与用户,反馈闭环,知识缺口报告以改进文档。
连接器
OAuth 与 API 连接器——内容留在来源侧;回答仅使用每位用户有权访问的内容。
具体连接器目录与部署选项按项目约定。
协作
文件与内容
系统与数据
关键指标
按部署约定的目标与 KPI——非一刀切数字
<3s
速度——首答时间(p95)
典型查询端到端;复杂智能体路径更长——见技术简报。
<20m
速度——更新传播(p95)
Webhook 连接器下从源变更到片段刷新的示意延迟;大批量环境按约定排期——按项目调优。
>90%
精度——有据质量
调优后典型目标:precision@k 和/或有据回答准确率 >90%,不支撑论断率 <1%——在各语料 hold-out 集上验证。
>85%
精度——召回与覆盖
答案存在于来源时,recall@k 与语料覆盖目标通常 >85%——用评测框架衡量,非虚荣基准。
50–70%
成本——相对朴素 RAG
启用路由、缓存、分块与压缩时的典型区间——示意,非保证。
可审计
可追溯——合规轨迹
记录查询、来源、模型与置信度,供合规流程使用。
对比分析
Microsoft 365 是一种基线;许多环境仍是搜索、维基与自建 RAG 的拼贴——示意模式,非针对特定厂商的主张。
| 因素 | Microsoft 365 Copilot | 典型企业模式 | Enterprise Knowledge AI |
|---|---|---|---|
| 来源覆盖 | 聚焦微软生态 | 各系统搜索与门户割裂。 | 广泛连接器覆盖常见企业来源 |
| 知识图谱 | 无关系推理层 | 关键词搜索,无图+向量多跳路径。 | 图+向量混合做多跳问答 |
| 模型选择 / BYOK | Azure OpenAI 路径 | 密钥与工具分散;策略不一致。 | 多模型路由与 BYOK |
| 部署 | 云服务模式 | SaaS 蔓延;缺乏统一受治理边界。 | 私有、混合或云——单一受治理层 |
| 商业视角 | 常为 M365 按席叙事 | 许可割裂;TCO 与治理碎片化。 | 按项目约定打包方式 |
部署选项
同一受治理知识层——由您选择数据、索引与推理的运行位置,从物理隔离到全托管云。
完全在您的环境内部署——索引与可选的自托管 LLM 留在您的网络。适合受监管与公共部门的最大控制。
在您的 AWS、Azure 或 GCP 租户中运行:数据与驻留留在您的边界,由 Thinkia 管理部署、升级与监控。
Thinkia 运营环境,默认优先欧盟。通过 OAuth 连接您系统的最快试点路径——无需客户自管基础设施。
常见问题
连接器在下次同步(Webhook 或计划)时检测变更。更新内容会重新分块与嵌入;删除会立即移除索引项并撤销访问。来源变更时可在日志中标记历史回答。
可以,在两者已连接且用户均有权访问时。图将记录系统中的实体与文档、消息关联,使回答可跨越合同语言与运营数据。
取决于语料规模与来源 API 限制。示意:小语料数小时;极大规模并行管道需数周。增量同步降低稳态成本——详见技术简报。
系统设计为仅从已检索且已授权上下文作答。证据薄弱或缺失时,会降低置信度、明示缺口或给出“来源不足”类结果——而非笃定臆测。阈值与升级行为可按风险取向调整。
企业部署范围限定,使您的语料不会混入公共模型的共享训练池。BYOK 或本地推理下,提供商按您的协议选择。具体条款在合同与 DPA 中——我们会在售前与安全评审中厘清。
否。欧盟《人工智能法》、NIST AI RMF 与 ISO/IEC 42001 的引用描述产品导向与文档模式——非对您用例的法律定性。监管定位请咨询法律顾问,并参阅 Thinkia 治理页面获取一般导向。
冲突论断会同时引用双方来源并标出冲突。系统不会悄悄选边—— resolution 由知识所有者负责。冲突率可作为质量信号跟踪。
默认路由对简单查询用较小模型,对复杂推理用较大模型。BYOK 可接入您偏好的提供商。本地部署可使用已批准的开放权重模型。
索引构建时带入来源身份与权利。查询时检索与综合仅使用调用者可见的片段——与 SharePoint、Confluence、Drive 或您的权威来源规则一致。若用户在源系统无法打开文档,则不应出现在其回答上下文中。
典型模式:私有租户、混合(数据与索引在您侧、可选云编排)或托管云——视驻留、网络与采购而定。技术简报概述部署假设;我们在发现阶段对齐目标架构。
常见连接器包括 Microsoft 365 / SharePoint、Confluence、Google Drive 及类似文档库,外加 API 与内部仓库。定制或遗留系统通常通过 API、导出或专用连接器计划集成。优先来源在摄取路线图中约定。