




Hybrid Graph + Vektor
Semantische Ähnlichkeit und relationaler Kontext gemeinsam abgefragt — Präzision, die keines allein erreicht.
/ Enterprise Knowledge AI /
Enterprise Knowledge AI verbindet jedes Dokument, System und jede Datenquelle in einer einzigen governed Intelligence-Schicht — und liefert Ihren Teams sofortige, präzise, quellenbasierte Antworten.
Warum Unternehmenswissen bricht
Die meisten Organisationen haben mehr institutionelles Wissen, als sie abrufen können. Es liegt in Ordnern, die niemand durchsucht, Wikis, die niemand liest, und in den Köpfen weniger Experten. Ergebnis: doppelte Arbeit, langsame Entscheidungen und Wissensabgang.
SharePoint, Drive, Confluence, Notion, E-Mail, lokale Dateien — jedes Team hat sein System und sie verbinden sich selten.
Stichwortsuche findet Dateien. Sie beantwortet keine Fragen. Nutzer lesen weiter fünf Dokumente — wenn das Richtige überhaupt auftaucht.
Veraltete Richtlinien stehen neben aktuellen. Ungoverned AI darüber liefert falsche Antworten mit falscher Sicherheit.
Ohne Attribution, Confidence und Audit-Trail sind KI-Antworten in regulierten oder hochriskanten Umgebungen nicht akzeptabel.
Produktdefinition
Semantische Ähnlichkeit und relationaler Kontext gemeinsam abgefragt — Präzision, die keines allein erreicht.
Mehrstufiges Retrieval und Synthese — kein einzelner Vektor-Lookup — mit Lückenerkennung und erneutem Retrieval bei Bedarf.
Berechtigungen aus Quellsystemen, Durchsetzung zur Retrieval-Zeit, Trust-Scoring und unveränderliche Audit-Logs.
Enterprise-Orchestrierung, Model-Routing und Betriebsmuster der Thinkia-Synapse-Plattform.
Architektur
Connectoren (OAuth/API), semantisches Chunking, OCR für Scans, Metadaten erhalten, inkrementelle Sync zur Kostenkontrolle.
Vektorsuche für Ähnlichkeit; Knowledge Graph für Entitäten und Beziehungen (z. B. ersetzt, gilt_für, owned_by).
Query-Zerlegung, paralleles Retrieval, Ranking, grounded Synthese, Zitate und Confidence — mit Agent-Loop für komplexe Queries.
RBAC/ABAC, Quell-Vertrauenswerte, unveränderlicher Audit-Trail, Halluzinationskontrollen. EU-AI-Act-orientierte menschliche Aufsicht und Erklärbarkeit; ausgerichtet auf ISO/IEC 42001 und NIST-AI-RMF-Dokumentation.
Web-App, Teams, Slack, Browser-Erweiterung, einbettbares Widget, REST/Streaming-API, OpenAPI und SDKs.
Verweise auf EU AI Act, ISO/IEC 42001 und NIST AI RMF beschreiben Produktausrichtung und Dokumentationsmuster — keine Rechtsberatung für Ihren konkreten Anwendungsfall.
Retrieval-Loop auf einen Blick
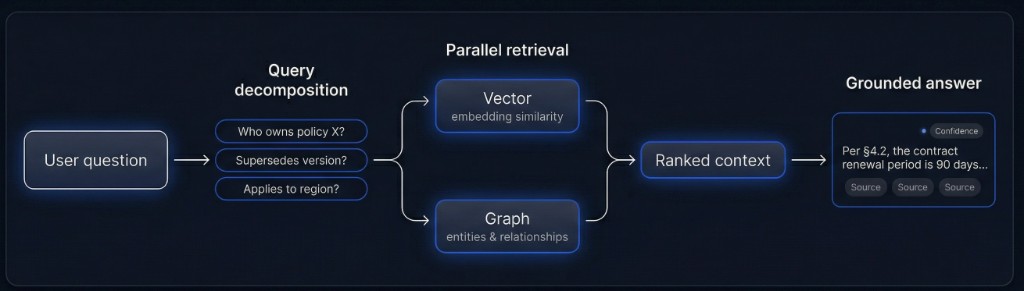
Komplexe Fragen werden vor dem Retrieval in Teilqueries zerlegt, um Rauschen und Tokenkosten zu senken.
Vektor- und Graph-Queries parallel; Ergebnisse gerankt, dedupliziert und trust-gewichtet.
Das Modell antwortet nur aus geranktem Kontext; Behauptungen verlinken auf Source-Chunks mit Confidence.
Implementierungspfad
Quellen, Volumen, Zugriffsmodelle und Prior-Use-Cases kartieren. Output: Architektur-Brief und Ingestionsplan.
Connectoren deployen, Chunking/Embedding/Graph-Extraktion, Zugriff konfigurieren. Output: durchsuchbare, berechtigungsbewusste Basis.
Retrieval-Qualität evaluieren, optionales Domain-Embedding-Fine-Tuning, Confidence-Schwellen. Output: validierter Qualitätsreport.
Pilot-Kohorte, Analytics zu Resolution und Eskalation, Baselines für Time-to-Answer. Output: Live-System mit Messung.
Quellen und Nutzer erweitern, Feedback-Loops, Knowledge-Gap-Reporting zur Dokumentationsverbesserung.
Connectoren
OAuth- und API-Connectoren — Inhalte bleiben an der Quelle; Antworten nutzen nur, was jede Person sehen darf.
Exakter Connector-Katalog und Deployment-Optionen werden pro Engagement vereinbart.
Zusammenarbeit
Dateien & Inhalte
Systeme & Daten
Metriken, die zählen
Ziele und KPIs vereinbaren wir pro Deployment — keine Einheitszahlen
<3s
Geschwindigkeit — Time-to-Answer (p95)
End-to-end für typische Queries; komplexe agentische Pfade länger — siehe technisches Briefing.
<20m
Geschwindigkeit — Update-Propagation (p95)
Illustrative Verzögerung von Quellenänderung zu frischen Chunks bei Webhook-Connectoren; batch-lastige Umgebungen nach Vereinbarung — pro Engagement getuned.
>90%
Präzision — Grounded Quality
Typische Ziele nach Tuning: precision@k und/oder Grounded-Answer-Accuracy >90%, Unsupported-Claim-Rate <1% — validiert auf Hold-out-Sets pro Korpus.
>85%
Präzision — Recall & Abdeckung
Recall@k und Corpus-Coverage typischerweise >85%, wo die Antwort in Quellen liegt — gemessen mit Eval-Harnesses.
50–70%
Kosten — vs. naives RAG
Typische Spanne mit Routing, Caching, Chunking und Kompression — illustrativ, keine Garantie.
Audit-ready
Nachvollziehbarkeit — Compliance-Trail
Query, Quellen, Modell und Confidence für Compliance-Workflows geloggt.
Vergleichsanalyse
Microsoft 365 ist eine Baseline; viele Landschaften haben noch ein Flickwerk aus Suche, Wikis und DIY-RAG — illustrative Muster, keine herstellerspezifischen Behauptungen.
| Faktor | Copilot für M365 | Typisches Enterprise-Muster | Enterprise Knowledge AI |
|---|---|---|---|
| Quellenabdeckung | Fokus Microsoft-Ökosystem | Fragmentierte Suche und Portale je System. | Breite Connector-Strategie über Enterprise-Quellen |
| Knowledge Graph | Keine relationale Reasoning-Schicht | Stichwortsuche ohne Graph+Vektor-Pfad für Multi-Hop. | Graph+Vektor-Hybrid für Multi-Hop-Fragen |
| Modellwahl / BYOK | Azure-OpenAI-Pfad | Verstreute Keys und Tools; uneinheitliche Policy. | Multi-Model-Routing und BYOK-Optionen |
| Deployment | Cloud-Service-Modell | SaaS-Zersplitterung; keine einheitliche governed Grenze. | Privat, hybrid oder Cloud — eine governed Schicht |
| Kommerzielle Sicht | Oft pro Seat (M365-Narrativ) | Silos mit Lizenzen; fragmentierte TCO-Story. | Packaging pro Engagement vereinbart |
Bereitstellungsoptionen
Dieselbe governed Knowledge-Schicht — Sie wählen, wo Daten, Indizes und Inferenz laufen, von air-gapped bis voll verwalteter Cloud.
Volles Deployment in Ihrer Landschaft — Indizes und optionale selbst gehostete LLMs bleiben in Ihrem Netz. Maximale Kontrolle für regulierten und öffentlichen Sektor.
In Ihrem AWS-, Azure- oder GCP-Tenant: Daten und Residency in Ihrer Grenze, Thinkia-managed Deployment, Upgrades und Monitoring.
Thinkia-betriebene Umgebung, EU-first standardmäßig. Schnellster Pilot-Pfad mit OAuth-Connectoren zu Ihren Systemen — keine Kunden-Infra zu betreiben.
FAQ
Connectoren erkennen Änderungen beim nächsten Sync (Webhook oder Schedule). Aktualisierter Inhalt wird neu gechunked und eingebettet; Löschungen entfernen Index-Einträge und widerrufen Zugriff sofort. Historische Antworten können in Logs markiert werden.
Ja, wenn beides angebunden ist und der Nutzer berechtigt ist. Der Graph verknüpft Entitäten aus Systemen of Record mit Dokumenten und Nachrichten, sodass Antworten Vertrags- und Betriebsdaten spannen können.
Hängt von Korpusgröße und API-Limits der Quelle ab. Indikativ: kleine Korpora in Stunden; sehr große in Wochen mit parallelen Pipelines. Inkrementeller Sync hält laufende Kosten niedrig — Details im technischen Briefing.
Das System antwortet aus abgerufenem, berechtigtem Kontext. Bei dünner oder fehlender Evidenz: niedrigere Confidence, explizite Lücken oder klares „nicht genug in den Quellen“ — kein sicher wirkendes Raten. Schwellen und Eskalation sind an Ihre Risikoposition anpassbar.
Enterprise-Deployments sind so begrenzt, dass Ihr Korpus nicht in einen gemeinsamen Trainingspool öffentlicher Modelle gemischt wird. Mit BYOK oder On-Prem-Inferenz werden Provider unter Ihren Vereinbarungen gewählt. Exakte Bedingungen stehen in Vertrag und DPA — wir klären das in Pre-Sales und Security Review.
Nein. EU AI Act, NIST AI RMF und ISO/IEC 42001 beschreiben Produktorientierung und Dokumentationsmuster — keine rechtliche Einordnung Ihres Falls. Für regulatorische Positionierung: Ihre Juristen und Thinkias Governance-Seiten zur allgemeinen Orientierung.
Widersprüchliche Behauptungen werden mit beiden Quellen und markiertem Konflikt angezeigt. Das System wählt nicht still einen Gewinner — Auflösung bleibt beim Knowledge Owner. Konfliktrate kann als Qualitätssignal dienen.
Standard: Routing mit kleineren Modellen für einfache Queries und größeren für komplexes Reasoning. BYOK bringt Ihre bevorzugten Provider. On-Prem: freigegebene Open-Weights-Modelle.
Der Index wird mit Quellidentität und Entitlements gebaut. Zur Query-Zeit nutzen Retrieval und Synthese nur Chunks, die der Aufrufer sehen darf — dieselben Regeln wie in SharePoint, Confluence, Drive oder Ihrer Source of Truth. Wer ein Dokument in der Quelle nicht öffnen kann, sollte es nicht im Antwortkontext sehen.
Typische Muster: privater Tenant, hybrid (Daten und Index bei Ihnen, optionale Cloud-Orchestrierung) oder managed Cloud — je nach Residency, Netz und Beschaffung. Das technische Briefing skizziert Annahmen; Zielarchitektur klären wir in Discovery.
Gängige Connectoren: Microsoft 365 / SharePoint, Confluence, Google Drive und ähnliche Dokumentenspeicher plus APIs und interne Repos. Custom oder Legacy meist via API, Export oder dediziertem Connector-Plan. Prior-Quellen werden in der Ingestions-Roadmap vereinbart.
Get started
Erzählen Sie uns von Quellen, Zugriffsmodell und Teams. Wir melden uns mit einem klaren nächsten Schritt — Orientierung, Pilotumfang oder Governance-Hinweise — ohne harten Verkauf.