




Grafo ibrido + vettore
Similarità semantica e contesto relazionale interrogati insieme per una precisione che nessuno dei due raggiunge da solo.
/ Enterprise Knowledge AI /
Enterprise Knowledge AI collega ogni documento, sistema e fonte dati in un unico layer di intelligenza governato — e offre al tuo team risposte istantanee, precise e ancorate alle fonti.
Perché la conoscenza aziendale si rompe
La maggior parte delle organizzazioni ha più sapere istituzionale di quanto riesca a consultare. Sta in cartelle che nessuno naviga, wiki che nessuno legge e nella testa di pochi esperti. Risultato: lavoro duplicato, decisioni lente e conoscenza che esce dalla porta.
SharePoint, Drive, Confluence, Notion, email, file locali — ogni team ha il suo sistema e raramente si collegano.
La ricerca per parole chiave trova file. Non risponde alle domande. Gli utenti leggono ancora cinque documenti — se emerge quello giusto.
Policy obsolete accanto a quelle attuali. IA non governata sopra quello stack restituisce errori con aria di certezza.
Senza attribuzione, confidenza e audit trail, le risposte IA non sono accettabili in ambienti regolati o ad alto rischio.
Definizione del prodotto
Similarità semantica e contesto relazionale interrogati insieme per una precisione che nessuno dei due raggiunge da solo.
Retrieval e sintesi multi-step — non un singolo lookup vettoriale — con rilevamento lacune e nuovo retrieval se serve.
Permessi ereditati dai sistemi sorgente, enforcement al momento del retrieval, punteggi di fiducia e log di audit immutabili.
Orchestrazione enterprise, routing modelli e pattern operativi dalla piattaforma Thinkia Synapse.
Architettura
Connettori (OAuth/API), chunking semantico, OCR per scansioni, metadati preservati, sync incrementale per controllare i costi.
Ricerca vettoriale per similarità; knowledge graph per entità e relazioni (es. sostituisce, si_applica_a, di_proprietà_di).
Scomposizione query, retrieval parallelo, ranking, sintesi fondata, citazioni e confidenza — con loop agente per query complesse.
RBAC/ABAC, punteggi fiducia fonte, audit trail immutabile, controlli allucinazione. Supervisione umana e spiegabilità orientate EU AI Act; allineamento con ISO/IEC 42001 e documentazione NIST AI RMF.
Web app, Teams, Slack, estensione browser, widget incorporabile, API REST/streaming, OpenAPI e SDK.
I riferimenti a EU AI Act, ISO/IEC 42001 e NIST AI RMF descrivono orientamento del prodotto e schemi di documentazione — non consulenza legale sul tuo caso specifico.
Loop di retrieval a colpo d’occhio
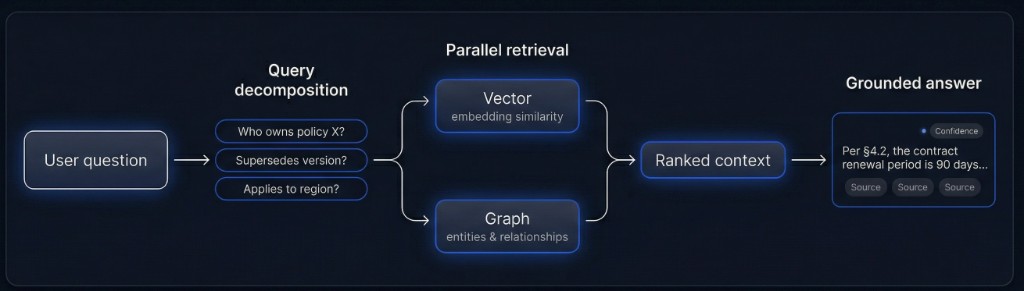
Domande complesse divise in sub-query prima del retrieval per ridurre rumore e costo token.
Query vettoriali e a grafo insieme; risultati rankeati, deduplicati e ponderati per fiducia.
Il modello risponde solo dal contesto rankeato; le affermazioni collegano chunk sorgente con confidenza.
Percorso di implementazione
Mappare fonti, volumi, modelli di accesso e use case prioritari. Output: brief architettura e piano ingestione.
Deploy connettori, chunking/embedding/estrazione grafo, configurare accesso. Output: base ricercabile e consapevole dei permessi.
Valutare qualità retrieval, fine-tune opzionale embedding dominio, soglie confidenza. Output: report qualità validato.
Coorte pilota, analytics su risoluzione e escalation, baseline time-to-answer. Output: sistema live con misurazione.
Espandere fonti e utenti, feedback loop, reporting lacune conoscenza per migliorare documentazione.
Connettori
Connettori OAuth e API — i contenuti restano alla fonte; le risposte usano solo ciò che ogni utente può vedere.
Catalogo connettori esatto e opzioni deploy concordate per engagement.
Collaborazione
File e contenuti
Sistemi e dati
Metriche che contano
Obiettivi e KPI che concordiamo per deploy — non numeri unici per tutti
<3s
Velocità — time-to-answer (p95)
End-to-end per query tipiche; percorsi agentici complessi più lunghi — vedi brief tecnico.
<20m
Velocità — propagazione aggiornamenti (p95)
Ritardo illustrativo da cambio fonte a chunk aggiornati con webhook; ambienti molto batch seguono schedule concordati — tuning per engagement.
>90%
Precisione — qualità fondata
Target tipici post-tuning: precision@k e/o accuratezza risposta fondata >90%, tasso affermazioni non supportate <1% — validato su hold-out per corpus.
>85%
Precisione — recall e copertura
Obiettivi recall@k e copertura corpus di solito >85% dove la risposta esiste nelle fonti — misurato con harness di valutazione.
50–70%
Costo — vs RAG naive
Range tipico con routing, cache, chunking e compressione — illustrativo, non garanzia.
Audit-ready
Tracciabilità — trail compliance
Query, fonti, modello e confidenza loggati per workflow compliance.
Analisi comparativa
Microsoft 365 è una baseline; molti ambienti hanno ancora un patchwork di ricerca, wiki e RAG fai-da-te — pattern illustrativi, non affermazioni specifiche del vendor.
| Fattore | Copilot per M365 | Pattern enterprise tipico | Enterprise Knowledge AI |
|---|---|---|---|
| Copertura fonti | Focus ecosistema Microsoft | Ricerca e portali frammentati per sistema. | Connettori estesi su fonti enterprise |
| Knowledge graph | Nessun layer relazionale equivalente | Ricerca keyword senza percorso grafo+vettore multi-hop. | Ibrido grafo + vettore per multi-hop |
| Scelta modello / BYOK | Percorso Azure OpenAI | Key e tool sparsi; policy disomogenea. | Routing multi-modello e opzioni BYOK |
| Deployment | Modello servizio cloud | SaaS frammentato; nessun perimetro unico governato. | Privato, ibrido o cloud: un layer governato |
| Lente commerciale | Spesso per posto (narrativa M365) | Licenze in silos; TCO e governance frammentati. | Packaging concordato per engagement |
Opzioni di deployment
Stesso layer di conoscenza governato — scegli dove girano dati, indici e inferenza, da air-gapped a cloud completamente gestita.
Deployment completo nel tuo perimetro — indici e LLM self-hosted opzionali restano sulla tua rete. Massimo controllo per uso regolato e pubblico.
Nel tuo tenant AWS, Azure o GCP: dati e residency nel tuo perimetro, con deployment, upgrade e monitoring gestiti da Thinkia.
Ambiente operato da Thinkia, UE-first di default. Percorso più rapido al pilota con connettori OAuth ai tuoi sistemi — nessuna infra cliente da gestire.
FAQ
I connettori rilevano le modifiche al prossimo sync (webhook o schedule). Contenuto aggiornato viene ri-chunkato e ri-embeddato; le eliminazioni rimuovono voci indice e revocano accesso subito. Risposte storiche possono essere segnate nei log.
Sì, quando entrambi sono collegati e l’utente è autorizzato. Il grafo collega entità dai sistemi di record a documenti e messaggi così le risposte possono coprire linguaggio contrattuale e dati operativi.
Dipende da dimensione corpus e limiti API fonte. Indicativo: corpus piccoli in ore; molto grandi in settimane con pipeline parallele. Sync incrementale mantiene bassi i costi in regime — dettagli nel brief tecnico.
Il sistema risponde da contesto recuperato e autorizzato. Con evidenza scarsa o assente: confidenza più bassa, lacune esplicite o esito chiaro tipo «non abbastanza nelle fonti» — non un tentativo sicuro. Soglie e escalation regolabili sul profilo di rischio.
I deployment enterprise sono delimitati così che il corpus non si mescoli in un pool di training condiviso per modelli pubblici. Con BYOK o inferenza on-prem i provider sono scelti secondo i tuoi accordi. Termini esatti in contratto e DPA — mappiamo in pre-sales e security review.
No. EU AI Act, NIST AI RMF e ISO/IEC 42001 descrivono orientamento prodotto e pattern documentali — non classificazione legale del tuo caso. Per posizionamento normativo: i tuoi legali e le pagine governance Thinkia per orientamento generale.
Affermazioni in conflitto sono mostrate con entrambe le fonti citate e conflitto evidenziato. Il sistema non sceglie silenziosamente — la risoluzione resta al knowledge owner. Il tasso di conflitto può essere tracciato come segnale di qualità.
Di default il routing usa modelli più piccoli per query semplici e più grandi per ragionamento complesso. BYOK porta i tuoi provider preferiti. On-prem: modelli open-weights approvati.
L’indice è costruito con identità fonte e diritti. Al momento della query retrieval e sintesi usano solo chunk consentiti — stesse regole di SharePoint, Confluence, Drive o source of truth. Se l’utente non può aprire un documento in origine, non dovrebbe apparire nel contesto risposta.
Pattern tipici: tenant privato, ibrido (dati e indice da voi, orchestrazione cloud opzionale) o cloud gestita — in base a residency, rete e procurement. Il brief tecnico delinea le assunzioni; allineiamo l’architettura target in discovery.
Connettori comuni: Microsoft 365 / SharePoint, Confluence, Google Drive e archivi documentali simili, più API e repository interni. Custom o legacy di solito via API, export o piano connettore dedicato. Fonti prioritarie concordate nella roadmap ingestione.
Get started
Raccontaci fonti, modello di accesso e team. Ti risponderemo con un passo successivo chiaro — orientamento, ambito pilota o riferimenti governance — senza pressione commerciale.