




Grafo híbrido + vector
Similitud semántica y contexto relacional consultados juntos para una precisión que ninguno logra solo.
/ Enterprise Knowledge AI /
Enterprise Knowledge AI conecta cada documento, sistema y fuente de datos en una única capa de inteligencia gobernada y ofrece a tu gente respuestas instantáneas, precisas y ancladas en las fuentes.
Por qué falla el conocimiento en la empresa
La mayoría de las organizaciones tienen más conocimiento institucional del que pueden consultar. Vive en carpetas que nadie recorre, wikis que nadie lee y en la cabeza de unos pocos expertos. Resultado: trabajo duplicado, decisiones lentas y conocimiento que se marcha por la puerta.
SharePoint, Drive, Confluence, Notion, correo, archivos locales: cada equipo tiene su sistema y casi nunca se conectan.
La búsqueda por palabras clave encuentra archivos. No responde preguntas. La gente sigue leyendo cinco documentos, si aparece el correcto.
Políticas antiguas conviven con las vigentes. La IA sin gobernanza encima de esa pila devuelve errores con apariencia de certeza.
Sin atribución, confianza y trazabilidad, las respuestas de la IA no son aceptables en entornos regulados o de alto riesgo.
Definición del producto
Similitud semántica y contexto relacional consultados juntos para una precisión que ninguno logra solo.
Recuperación y síntesis en varios pasos, no una sola consulta vectorial, con detección de lagunas y nueva recuperación cuando hace falta.
Permisos heredados de los sistemas de origen, aplicación en tiempo de recuperación, puntuación de confianza y registros de auditoría inmutables.
Orquestación enterprise, enrutado de modelos y patrones operativos de la plataforma Thinkia Synapse.
Arquitectura
Conectores (OAuth/API), troceado semántico, OCR para escaneos, metadatos preservados, sincronización incremental para controlar coste.
Búsqueda vectorial por similitud; grafo de conocimiento para entidades y relaciones (p. ej. sustituye, aplica_a, propiedad_de).
Descomposición de consultas, recuperación paralela, ranking, síntesis fundamentada, citas y confianza, con bucle de agente para consultas complejas.
RBAC/ABAC, puntuaciones de confianza por fuente, trazabilidad inmutable, controles de alucinación. Supervisión humana y explicabilidad orientadas al EU AI Act; alineación con ISO/IEC 42001 y documentación NIST AI RMF.
Web app, Teams, Slack, extensión de navegador, widget embebible, API REST/streaming, OpenAPI y SDKs.
Las referencias al EU AI Act, ISO/IEC 42001 y NIST AI RMF describen la orientación del producto y patrones de documentación; no constituyen asesoramiento legal sobre su caso concreto.
Bucle de recuperación en un vistazo
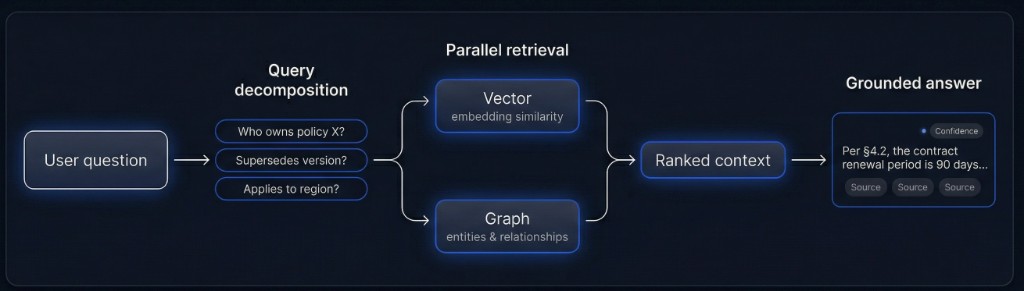
Las preguntas complejas se dividen en subconsultas antes de recuperar para reducir ruido y coste de tokens.
Consultas vectoriales y de grafo en paralelo; resultados rankeados, deduplicados y ponderados por confianza.
El modelo responde solo a partir del contexto rankeado; las afirmaciones enlazan a trozos fuente con confianza.
Camino de implementación
Mapear fuentes, volúmenes, modelos de acceso y casos de uso prioritarios. Entregable: informe de arquitectura y plan de ingesta.
Desplegar conectores, ejecutar troceado/embeddings/extracción de grafo, configurar acceso. Entregable: base consultable y consciente de permisos.
Evaluar calidad de recuperación, ajuste fino opcional de embeddings de dominio, umbrales de confianza. Entregable: informe de calidad validado.
Cohorte piloto, analítica de resolución y escalado, líneas base de tiempo hasta respuesta. Entregable: sistema en vivo con medición.
Ampliar fuentes y usuarios, bucles de feedback, informes de lagunas de conocimiento para mejorar la documentación.
Conectores
Conectores OAuth y API: el contenido sigue en origen; las respuestas usan solo lo que cada usuario puede ver.
El catálogo exacto de conectores y opciones de despliegue se acuerdan por proyecto.
Colaboración
Archivos y contenido
Sistemas y datos
Métricas que importan
Objetivos e KPI que acordamos por despliegue, no cifras únicas para todos
<3s
Velocidad — tiempo hasta respuesta (p95)
De extremo a extremo para consultas típicas; rutas agénticas complejas más largas — ver ficha técnica.
<20m
Velocidad — propagación de actualizaciones (p95)
Retraso ilustrativo desde el cambio en origen hasta trozos refrescados con conectores por webhook; entornos muy por lotes siguen calendarios acordados — afinado por proyecto.
>90%
Precisión — calidad fundamentada
Objetivos típicos tras afinado: precision@k y/o precisión de respuesta fundamentada >90%, tasa de afirmaciones no soportadas <1% — validado en conjuntos hold-out por corpus.
>85%
Precisión — recall y cobertura
Objetivos de recall@k y cobertura del corpus habitualmente >85% cuando la respuesta existe en fuentes — medido con arneses de evaluación, no benchmarks vanidosos.
50–70%
Coste — frente a RAG ingenuo
Rango típico con enrutado, caché, troceado y compresión activados — ilustrativo, no garantía.
Listo para auditoría
Trazabilidad — pista de cumplimiento
Consulta, fuentes, modelo y confianza registrados para flujos de cumplimiento.
Análisis comparativo
Microsoft 365 es una línea base; muchos entornos siguen con búsquedas, wikis y RAG casero — patrones ilustrativos, no afirmaciones específicas de proveedor.
| Factor | Copilot para M365 | Patrón empresarial típico | Enterprise Knowledge AI |
|---|---|---|---|
| Cobertura de fuentes | Enfoque en ecosistema Microsoft | Búsquedas y portales fragmentados por sistema. | Conectores amplios sobre fuentes habituales |
| Grafo de conocimiento | Sin capa de razonamiento relacional | Búsqueda por palabras sin camino grafo+vector multi-salto. | Híbrido grafo + vector para multi-salto |
| Elección de modelo / BYOK | Vía Azure OpenAI | Claves y herramientas dispersas; política desigual. | Enrutado multi-modelo y opciones BYOK |
| Despliegue | Modelo de servicio en la nube | SaaS disperso; sin un único perímetro gobernado. | Privado, híbrido o nube: una capa gobernada |
| Enfoque comercial | A menudo por puesto (narrativa M365) | Licencias en silos; TCO y gobernanza fragmentados. | Empaquetado acordado por proyecto |
Opciones de despliegue
La misma capa de conocimiento gobernada: tú eliges dónde corren datos, índices e inferencia, desde air-gapped hasta nube gestionada.
Despliegue completo dentro de tu perímetro: índices y LLM autoalojados opcionales permanecen en tu red. Máximo control para uso regulado y sector público.
En tu tenant AWS, Azure o GCP: datos y residencia en tu perímetro, con despliegue, actualizaciones y monitorización gestionados por Thinkia.
Entorno operado por Thinkia, con prioridad UE por defecto. Camino más rápido al piloto con conectores a tus sistemas vía OAuth, sin infraestructura del cliente que ejecutar.
FAQ
Los conectores detectan cambios en la siguiente sincronización (webhook o programación). El contenido actualizado se vuelve a trocear y embeber; las eliminaciones quitan entradas del índice y revocan el acceso al instante. Las respuestas históricas pueden marcarse en registros cuando cambian las fuentes.
Sí, cuando ambos están conectados y el usuario tiene derecho a ambos. El grafo enlaza entidades de sistemas de registro con documentos y mensajes para que las respuestas abarquen lenguaje contractual y datos operativos.
Depende del tamaño del corpus y de los límites de la API de origen. Indicativo: corpus pequeños en horas; corpus muy grandes en semanas con pipelines paralelos. La sincronización incremental mantiene bajo el coste en régimen estable — detalles en la ficha técnica.
El sistema está pensado para responder solo con contexto recuperado y autorizado. Cuando la evidencia es escasa o falta, obtienes menor confianza, lagunas explícitas o un resultado claro tipo «no hay suficiente en las fuentes», no una suposición con apariencia de certeza. Los umbrales y la escalada se pueden afinar según tu postura de riesgo.
Los despliegues enterprise están acotados para que tu corpus no se mezcle en un pool de entrenamiento compartido de modelos públicos. Con BYOK o inferencia on-prem, los proveedores de modelo se eligen bajo tus acuerdos. Los términos exactos van en contrato y DPA; lo detallamos en preventa y revisión de seguridad.
No. Las referencias al EU AI Act, NIST AI RMF e ISO/IEC 42001 describen orientación del producto y patrones de documentación, no una clasificación legal de tu caso. Para posicionamiento regulatorio, consulta a tu asesor y revisa las páginas de gobernanza de Thinkia para orientación general.
Las afirmaciones en conflicto se muestran citando ambas fuentes y marcando el conflicto. El sistema no elige un ganador en silencio: la resolución queda con el propietario del conocimiento. La tasa de conflicto puede seguirse como señal de calidad.
Por defecto, el enrutado usa modelos más pequeños para consultas simples y mayores para razonamiento complejo. BYOK permite traer tus proveedores preferidos. Los despliegues on-prem pueden usar modelos de pesos abiertos aprobados.
El índice se construye con identidad de origen y derechos. En tiempo de consulta, la recuperación y la síntesis solo usan trozos que el solicitante puede ver: las mismas reglas que en SharePoint, Confluence, Drive o tu fuente de verdad. Si un usuario no puede abrir un documento en el origen, no debería aparecer en su contexto de respuesta.
Patrones típicos: tenant privado, híbrido (datos e índice en tu lado, orquestación en nube opcional) o nube gestionada, según residencia, red y compras. La ficha técnica describe supuestos de despliegue; alineamos la arquitectura objetivo en la fase de descubrimiento.
Conectores habituales incluyen Microsoft 365 / SharePoint, Confluence, Google Drive y almacenes de documentos similares, más APIs y repositorios internos. Sistemas personalizados o legado suelen integrarse vía API, exportación o plan de conector dedicado. Las fuentes prioritarias se acuerdan en la hoja de ruta de ingesta.
Get started
Cuéntanos tus fuentes, modelo de acceso y equipos. Te responderemos con un siguiente paso claro — orientación, alcance de un piloto o pistas de gobernanza — sin presión comercial.